Was es mit Big Data auf sich hat und warum mehr nicht zwangsläufig immer besser ist.
Wer oder was ist eigentlich dieses „Big Data“?
Ein Datum steht für eine qualitative Angabe oder einen quantitativen Wert. Beispiel: „Frau S. ist 45 Jahre alt, 1.62m groß und arbeitet als Architektin“. Aus der Beschreibung von Frau S. können wir folgende Daten über sie ableiten: Geschlecht = weiblich, Alter = 45 Jahre, Größe = 1.62 m, Beruf = Architektin. Das erinnert jetzt ein wenig an Textaufgaben in der Schule, aber so einfach ist das Konzept hinter Daten.
Die zunehmende Digitalisierung führt nun dazu, dass wir nicht nur demografische Daten über unsere Frau S. erheben können, sondern mittlerweile auch wissen, mit wem sie befreundet ist, wohin sie gerne in Urlaub fährt, welches Deo sie am liebsten kauft, wo und wie regelmäßig, bei welcher Krankenkasse sie versichert ist und so weiter. Jeder Mensch erzeugt mehr als ein Gigabyte Daten pro Tag, bezogen auf über 7,5 Milliarden Menschen i. S. v. Datenproduzenten ergibt sich so eine unvorstellbare Menge an Daten, die täglich wächst.
Vor diesem Hintergrund spricht man heute von „Big Data“. Dabei referenziert der Begriff nicht nur auf die bloße Menge, wie man irrtümlicherweise annehmen könnte. „Big Data“ steht für Daten, die im Volumen überdurchschnittlich groß (Volume), deren Entstehungsgeschwindigkeit und Übertragung außerordentlich schnell (Velocity) und deren Heterogenität bezogen auf die vorliegenden Datentypen sehr ausgeprägt ist (Variety).
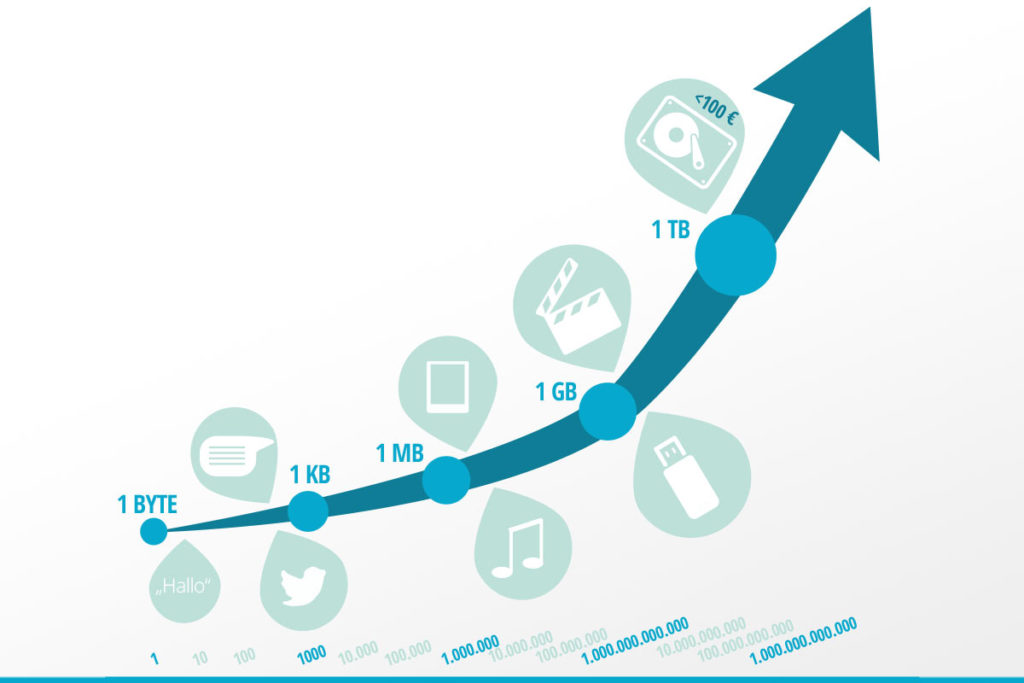
Big Data: Viel hilft viel … oder?
Für Unternehmen ergeben sich vielfältige Potenziale durch „Big Data“. Basierend auf der rasant wachsenden Menge tagesaktueller unterschiedlicher Daten können beispielsweise Prognosen über zukünftige Absatzentwicklungen berechnet werden. Dank Big Data spielen bei der Vorhersage der Absatzentwicklung für ein Kosmetikprodukt nicht mehr nur Informationen über die abgesetzte Menge zum Zeiptunkt x eine Rolle, sondern es fließen zusätzliche Informationen über Ferien, Feiertage, das Wetter, Werbung, Promotion-Aktionen, gesellschaftliche und mediale Trends etc. in die Prognose mit ein. Big Data ermöglicht uns eine ganzheitliche, dynamische Betrachtung auf ein statisches Ergebnis (hier Absatzmenge). Big Data ist also der Versuch, die Kaufentscheidung des Kunden unter Berücksichtigung seines gesamten individuellen Ökosystems zu erklären und zu antizipieren.
Aber auch bei dem Thema Datenanalyse gilt: Es kommt nicht nur auf die Menge an, sondern vor allem auf die Relevanz der Daten. Wenn ich beispielsweise basierend auf der Anzahl an Ballkontakten während eines Fußballspiels die Absatzmenge eines Shampoos prognostizieren möchte, wird das sehr wahrscheinlich nach hinten losgehen, und zwar unabhängig davon, wie viele Fußballspiele ich betrachte. Sofern ich aber die für meine Fragestellung relevanten Daten erhoben habe, kann es durchaus sein, dass auch wenige Daten interessante Ergebnisse liefern. Man kann also auch durchaus mit „Small Data“ Erfolge erzielen, und manchmal sogar wertvollere Insights gewinnen als über die bloße Masse.
Ein gutes Beispiel hierfür ist die Analyse von Kundenfeedback. Unternehmen analysieren Kundenfeedback, um herauszufinden, welche Probleme der Kunde im Feld beschreibt, was dem Kunden an einem Produkt gefällt oder eben nicht. Dabei sind die Themen, über die die Mehrheit der Kunden spricht, natürlich wichtig, aber i. d. R. nicht wirklich eine Überraschung für Unternehmen. Richtig interessant wird es, wenn es gelingt, die Themen zu identifizieren, über die nur zwei, drei Kunden sprechen. Gute Ideen entstehen nie in 1.000 Köpfen gleichzeitig, sondern eher in einem. Um einen Wettbewerbsvorsprung zu erzielen und innovative Produkte zu entwickeln, ist es also umso wichtiger, sich auch mal auf „Small Data“ einzulassen.
Künstliche Intelligenz, Machine Learning oder einfach Mathe?
Intelligenz ist Ansichtssache
Der bloße Besitz von Daten ist nutzlos. Daten gewinnen erst dann an Wert, wenn man sie analysiert. Dies geschieht mit mehr oder weniger komplexen mathematischen Verfahren, die sich unter dem Sammelbegriff „Künstliche Intelligenz“ (KI) verbergen. Unter KI verstehen wir all jene Verfahren, die dazu in der Lage sind, menschliche Intelligenz nachzuahmen. Die meisten KI-Systeme sind nach wie vor spezialisiert auf eng definierte Aufgabenbereiche: Googles AlphaGo oder der Supercomputer Deep Blue sind unantastbare Experten im Go bzw. Schach, allerdings auf dieses Gebiet beschränkt. Während Menschen über Allgemeinwissen, Vorerfahrung, Intuition, Adaption und Rituale mit Bezug auf verschiedene Wissensdomänen verfügen, ist dieses Wissen für Computer aktuell nicht zugänglich. Der Begriff „Intelligenz“ ist also Interpretationssache. Die Künstliche Intelligenz ist immer nur so clever, wie ihr „Bediener“. Zum heutigen Standpunkt spricht man daher auch von einer „schwachen Künstlichen Intelligenz“.
Wo nutzen wir KI?
Sind wir früher zum Teil mit großen, auf dem Lenkrad ausgebreiteten Straßenkarten von A nach B gefahren, haben bereits die ersten Navigationsgeräte die Kursbestimmung auf den Straßen verändert. Seitdem jetzt zusätzlich noch aktuelle, durch andere Nutzer aufgenommene Verkehrsdaten in die Routenermittlung mit einfließen, um Baustellen, Sperrungen und Staus vermeiden und weiträumig umfahren zu können, haben wir eine Vorstellung davon bekommen, was mit KI möglich ist. Navigationssysteme wie etwa Waze, Google Maps oder TomTom Go Mobile suchen zu jedem Zeitpunkt der Fahrt die aktuell schnellste Route, die einen zum Ziel führt.
Ein weiterer Bereich der KI ist die automatische Sprachverarbeitung. Der Nutzer kann seinen Wunsch äußern, die Maschinen übersetzen die Anfrage, bearbeiten sie und liefern die gewünschten Ergebnisse. Dies kann eine Navigation zu einer festen Adresse oder zu dem nächsten Schwimmbad sein, der Anruf bei einer Person aus dem Adressbuch kann genauso initiiert werden wie die Auswahl des besten Sushi-Restaurants in der Region. Die Antwort erfolgt per Bild, Text oder auch Sprachausgabe.
Das Westphalia DataLab (WDL) agiert seit seiner Gründung 2017 durch Cornelius Brosche, Prof. Dr. Reiner Kurzhals und dem Investor FIEGE Logistik schwerpunktmäßig im Bereich „Data Analytics as a Service“. Im Juli 2019 erhielt das WDL die Auszeichnung vom Center Smart Services der RWTH Aachen. Dort wurden mehr als 300 internationale Anbieter von Machine-Learning-Dienstleistungen im industriellen Umfeld im Rahmen einer internationalen Marktstudie untersucht. Das WDL wurde dabei als einziges Start-up und gemeinsam mit vier etablierten, internationalen Industrieunternehmen als „Machine Learning Champion“ ausgezeichnet.
Was ist Machine Learning und wo wird es eingesetzt?
Machine Learning (ML) ist ein Teilbereich der Künstlichen Intelligenz. ML-Algorithmen generieren ihr Wissen aus Erfahrungen. Dazu braucht die ML-Software relevante Daten, Algorithmen und Regeln, um anschließend selbstständig den Datenbestand zu analysieren und Muster bzw. Zusammenhänge erkennen zu können. Dazu wird beim ML mithilfe von Trainingsdaten ein statistisches Modell aufgebaut, welches Muster in den gegebenen Daten erkennt und lernt. Wichtig für das maschinelle Lernen ist das Vorhandensein repräsentativer Datenmengen, denn was der Algorithmus nicht kennt, erkennt er nicht.
Ein Unterbereich von Machine Learning ist Deep Learning (DL). Deep-Learning-Verfahren, zu denen u.a. Neuronale Netze gehören, sind inspiriert von der Struktur des menschlichen Gehirns. Während sich beim ML die Maschinen bereits selbstständig Zusammenhänge aus riesigen Datenmengen erschließen, trainieren sich die Maschinen beim DL mithilfe Neuronaler Netze und riesiger Datenmengen selbst. Die Leistung und die erzielten Ergebnisse sind nicht im Ansatz mit dem vergleichbar, was Menschen leisten können, wenngleich der Grundgedanke gleich ist.
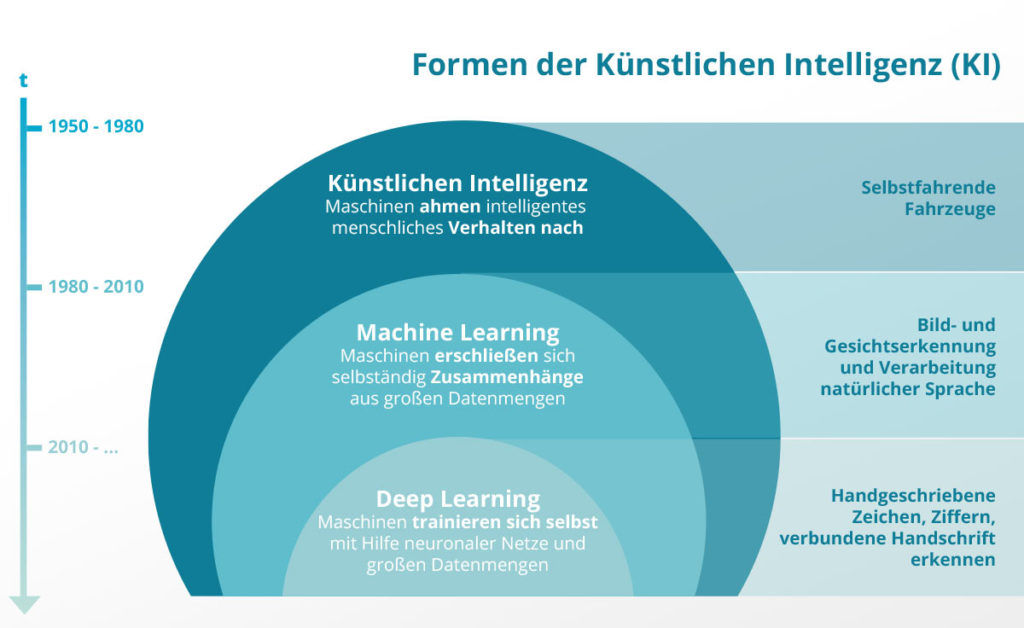
Was wurde aus Korrelation, Regression und Co.?
Vor lauter neuer englischer Begriffe geht vollkommen unter, dass die dahinterstehende Mathematik tatsächlich klassische Methoden verwendet. Machine Learning, Deep Learning oder Neuronale Netze basieren auf einer Vielzahl altbekannter Algorithmen, wie etwa Regressionsmethoden, Entscheidungsbäume, Klassifikations- und Regressionsbäume oder Random Forests, Clustering, Support Vector Machines und Principal Component Analysis.
Genauso wie mir der bloße Besitz von Daten nichts bringt, hilft mir auch das reine Verständnis über die diversen Analyseverfahren keinen Schritt weiter. Um Daten wertschöpfend nutzen zu können, brauchen Unternehmen Mitarbeiter, die die verschiedenen Analyseverfahren beherrschen. Dabei handelt es sich um die Berufsbilder „Data Scientist“ und „Data Analyst“. Beide Professionen haben es mit (sehr) großen, teilweise heterogenen und mal mehr oder weniger strukturierten Daten zu tun, aus denen für einen bestimmten Zweck Wissen extrahiert werden soll. Im besten Fall mit dem Ergebnis, neue Erkenntnisse generiert und Handlungsmaßnahmen indiziert zu haben.
Wer bin ich und was mache ich eigentlich hier?
Data Scientists extrahieren Daten aus unterschiedlichen Quellen, bereinigen diese, führen verschiedene Informationen zusammen und analysieren, mit vorher definierter Fragestellung oder ohne (explorativ), die Daten. Was den Teil der Analyse betrifft, so sind Data Scientists Experten bei der Anwendung von Methoden aus dem Bereich der Künstlichen Intelligenz und des Machine Learnings.

Wo Data Scientists sich häufig eine zu beantwortende Frage selber bzw. auf Basis der vorliegenden Datenbasis erschließen oder erarbeiten müssen, konzentrieren sich Datenanalysten vermehrt auf die Erklärung und Beantwortung von bereits bestehenden, bekannten und wiederkehrenden Fragestellungen im Unternehmen. Dies hat zur Folge, dass das Vorgehen bei der Datenanalyse entsprechend fokussierter abläuft und nicht selten auf einem bereits vorhandenen, d. h. kompilierten und vorstrukturierten Datenexport basiert.
Ist es die Aufgabe eines Data Scientist, die Zukunft vorherzusagen, so sind Datenanalysten oft schwerpunktmäßig für das (retrospektive) Reporting im Sinne von vorgegebenen KPIs oder Auswertungen im Bereich der „Business Intelligence“ zuständig. Für die Analyse von Kennzahlen werden dabei eher selten komplexe statistische Modelle verwendet, vielmehr finden hier grundlegende Methoden und Testverfahren aus der Statistik Anwendung.

 Teams")






 Teams")
Guter Artikel. „KI“ ist auch so ein Beispiel von Buzzword, über das viele sprechen, aber jeder ein wenig etwas anderes (und mancher auch gar nichts) meint. Dies ist ein guter Beitrag, um ein gemeinsames Grundverständnis des Themas zu schaffen.